概要
機械学習モデルやAIモデルを運用するにあたって、ABテストを行いたいケースが多くあります。
例えば、運用中の予測モデルAがあり、それに改善を加えたモデルBがあるとします。この時、オフラインの精度においてはBの方が精度が良かったとします。
ここで、Bをデプロイして以降の推論をBに100%任せて良いかというと、そうとも限りません。予測モデルなどの問題ではオフラインでいくら精度が良かろうと、オンラインでの精度が最も重要となるからです。つまり実際に運用された際のデータで精度が出ないと意味がない、ということです。
オフラインとオンラインのデータで分布が異なる可能性は大いにあります。そのため、オフラインで精度が出ていてもオンラインでは精度が出ないことが多々あります。
従って、ここで行いたいのはオンラインのデータにおけるABテストです。具体的には、モデルAとBの両方を平行して運用する期間を設け、その結果を見てどちらのモデルが良いかを判断することを考えます。
本記事では、この問題を解くことを考え、ベイズ推定に基づきPythonでシミュレーションを行います。
なお、ベイズのシミュレーションはPyMCの3系で行われる記事が多いですが、本記事ではPyMCの5系を用います。
どうやってモデルAとBの良し悪しを判断するか
本記事で扱うのは、どのような根拠を持って良し悪しを判断するか、です。
例えば、オンラインのデータを収集してそれぞれのモデルで10回ずつの推論結果が得られたとします。この時、それぞれの正解率が以下だったとします。
- モデルA: 3/10 (正解率30%)
- モデルB: 5/10 (正解率50%)
モデルBの方が正解率が良かったので、モデルBの方が精度が良い!…と判断したいところですが、果たして本当にそうでしょうか。
たまたま予測が容易なデータがモデルBに多く流れていたため、モデルBの精度が良く見えるだけかもしれません。10回ではなく、100回の結果であれば結論が異なるかもしれません。本当はモデルAの方が精度が良かった場合、この結果だけをもって判断すると精度が悪いモデルを選択することになるので、プロダクトの価値が下がってしまうでしょう。
ここで考えたいのは、できる限り確度が高い判断を行いたい、ということです。もちろん100%正しい判断は不可能ですが、ある程度の確度で精度が良い方を選択することは可能です。手法はいくつかありますが、ここではベイズ推定を用いてAとBの良し悪しを判断します。
ベイズ推定を用いてモデルのABテストを行う
ABテストを行う際の最もメジャーな手法は頻度論に基づく仮説検定です。一方で知見が多い反面取り回しがしにくい面が多いため、本記事ではベイズ推定によってABテストをします。
まずは必要なライブラリをインポートします。
import itertools
import logging
import arviz as az
import numpy as np
import pymc as pm
logging.getLogger('pymc').setLevel(logging.WARNING)問題設定
比較するものは前述のようにモデルAとモデルBの精度とします。そのモデルはシンプルに2択を当てるモデルとし、評価指標としてはAccuracyを採用します。つまり、ABテストの目的はオンラインデータに対してAccuracyが高いモデルを採用することです。
また、問題の簡略化のためにモデルリリース時に一部のオンラインデータをモデルAとモデルBの評価用に流せるという理想環境が整っているとします。データにバイアスは無く、理想的なランダムサンプリングができていると仮定し、かつモデルとデータの組み合わせに関するバイアスも無いとします。
加えて、予測したオンラインデータの真のラベルは予測後、当日中に手に入るとします。つまり予測の答え合わせはその日の夜にはできるということです。
上記を踏まえ、日次で得られたデータのAccuracyを比較をして、ある程度許容できる確度で精度が良い方がどちらかを判断する、という問題を解くことを考えます。
また、その日に結論が出せるほどの確度が無かった場合は、次の日に追加でデータを得て再度判定を行うとします。
(なお、後述しますが上記のような仮定を満たすプロジェクトは大変少なく、評価指標の設計やサンプリングの設計、システムの設計、ドメイン独自の何かなど課題が多くあるので留意してください。)
モデルとデータの用意
シミュレーションとして、モデルAとモデルBの真のAccuracyが以下だったとします。
- モデルA: 80%
- モデルB: 83%
上記を踏まえると、モデルBの方が精度が良いという判断ができれば嬉しい、と言えます。
また、手に入るオンラインデータは1日あたり100件とします。仮定から、モデルによる予測の正解数は二項分布に従うので、以下のような関数によってシミュレーション用のデータを生成します。
def generate_synthetic_data(true_accuracy, size):
return np.random.binomial(1, true_accuracy, size)オンラインデータでベイジアンAB
今回データから知りたいのは「各モデルの真の正解率がいくつか」であり、「その差がどの程度あるのか」です。
これが分かれば、どちらのモデルがどの程度優れていそうだからモデルA(or B)を選ぶことが可能です。今回は97%の確率でA(or B)の方が少しでも優れている、という結果が得られたら判断するとします。
また、このABテストをいつまでも繰り返している訳にはいかないので、開始から10日後に打ち切るとします。つまり、それまでに結論が得られなければ差はないと判断する、ということです。
ベイズ推定においては、この真の正解率の分布を推定し、そこから信用区間を求めて上記を判断します。今回、正解率の分布には二項分布の共役事前分布であるベータ分布を採用します。また、仮定から使える事前情報は特に無いため、α=1, β=1の無情報事前分布とします。
なお、本記事では実装がメインとなるため、詳しい理論や妥当性は後述の参考文献にお任せします。
では実装していきましょう。まず、初日の観測データを得られたとします。
daily_size = 100
true_accuracy_a = 0.80
true_accuracy_b = 0.83
observations_a = generate_synthetic_data(true_accuracy_a, daily_size)
observations_b = generate_synthetic_data(true_accuracy_b, daily_size)次に、前述の分布の設定に基づきベイズ推定によって事後分布を求めます。
# 事前分布設定(無情報なBeta分布)
alpha = 1
beta = 1
# 分布の更新
with pm.Model() as model:
# 事前分布(Beta分布、無情報な事前分布)
accuracy_a = pm.Beta('A', alpha=alpha, beta=beta)
accuracy_b = pm.Beta('B', alpha=alpha, beta=beta)
# 二項分布による正解数(観測データ)
pm.Binomial('daily_A', n=daily_size, p=accuracy_a, observed=sum(observations_a))
pm.Binomial('daily_B', n=daily_size, p=accuracy_b, observed=sum(observations_b))
# サンプリングによる事後分布の推定
inference_1 = pm.sample(progressbar=False)そしてAとBの事後分布、差の分布を可視化します。
# A, Bの正解率の事後分布の可視化
pm.plot_posterior(inference_1, show=True)
# 差を計算し、可視化
diff_1 = inference_1.posterior.B - inference_1.posterior.A
pm.plot_posterior(diff_1, show=True)結果は以下でした。
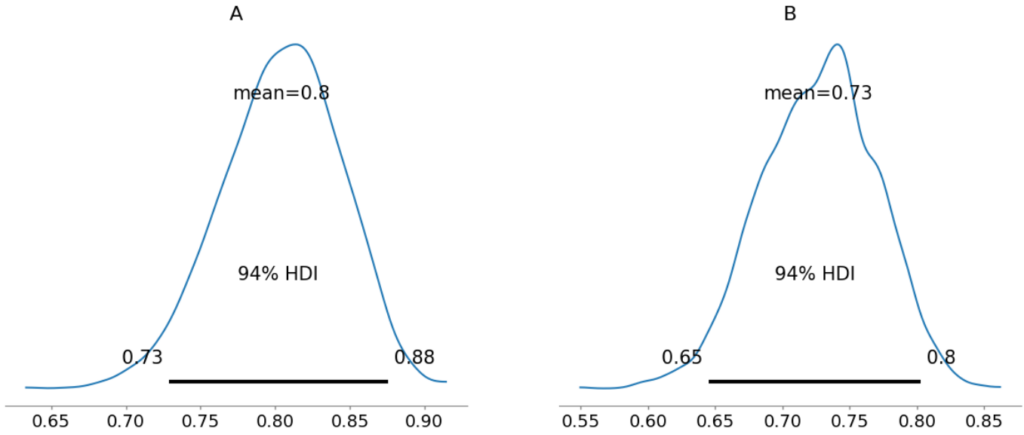
最後に、モデルBがモデルAより精度が良い確率を計算し、判定します。今回は差の分布の94%信用区間の下側が0以上か否かを確認します。
確認すると下側は-0.19となっているため、初日の時点では差があるとは言えない、と結論付けます。
1日目では結論が出せなかったので、2日目のデータも集まるのを待って分布を更新していきましょう。下記のように、データを観測し、事後分布を更新します。
# 2日目の観測データ
observations_a_2 = generate_synthetic_data(true_accuracy_a, daily_size)
observations_b_2 = generate_synthetic_data(true_accuracy_b, daily_size)
# 2日目の観測データを追加
with model:
# 事後分布を更新するために新しい日次データを追加
pm.Binomial(f'daily_A2', n=daily_size, p=accuracy_a, observed=sum(observations_a_2))
pm.Binomial(f'daily_B2', n=daily_size, p=accuracy_b, observed=sum(observations_b_2))
# 事後分布のサンプルを取得
inference_2 = pm.sample(progressbar=False)1日目と同様に可視化します。
# A, Bの正解率の事後分布の可視化
pm.plot_posterior(inference_2, show=True)
# 差を計算し、可視化
diff_2 = inference_2.posterior.B - inference_2.posterior.A
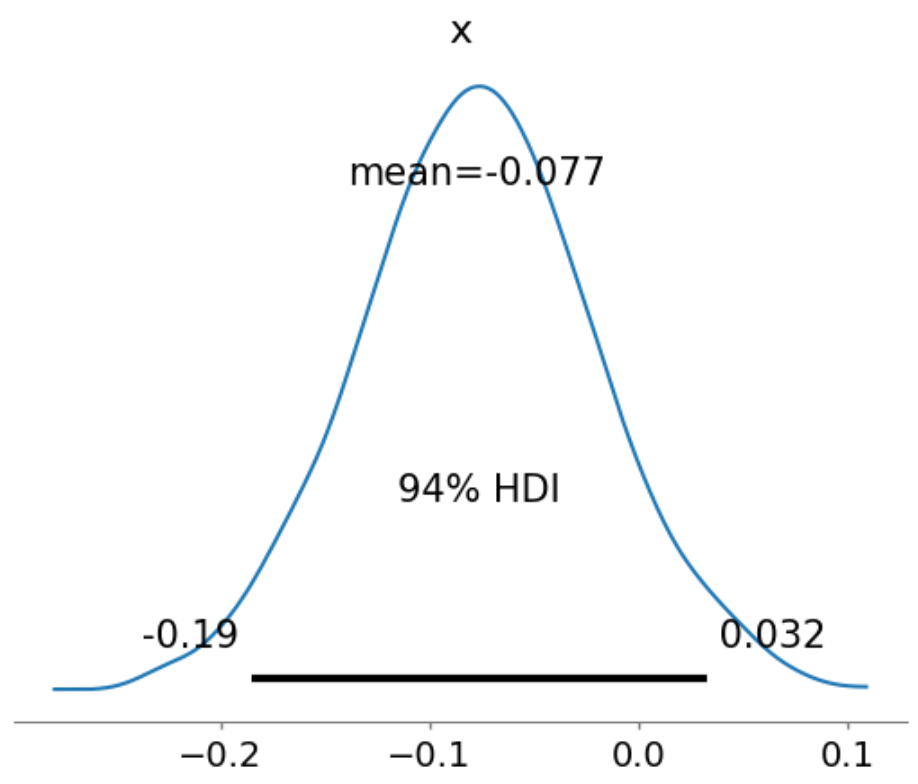
pm.plot_posterior(diff_2, show=True)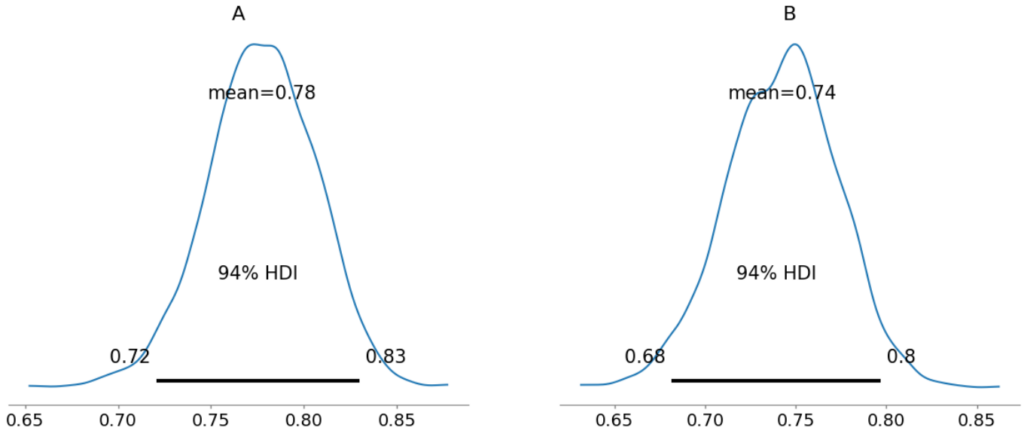
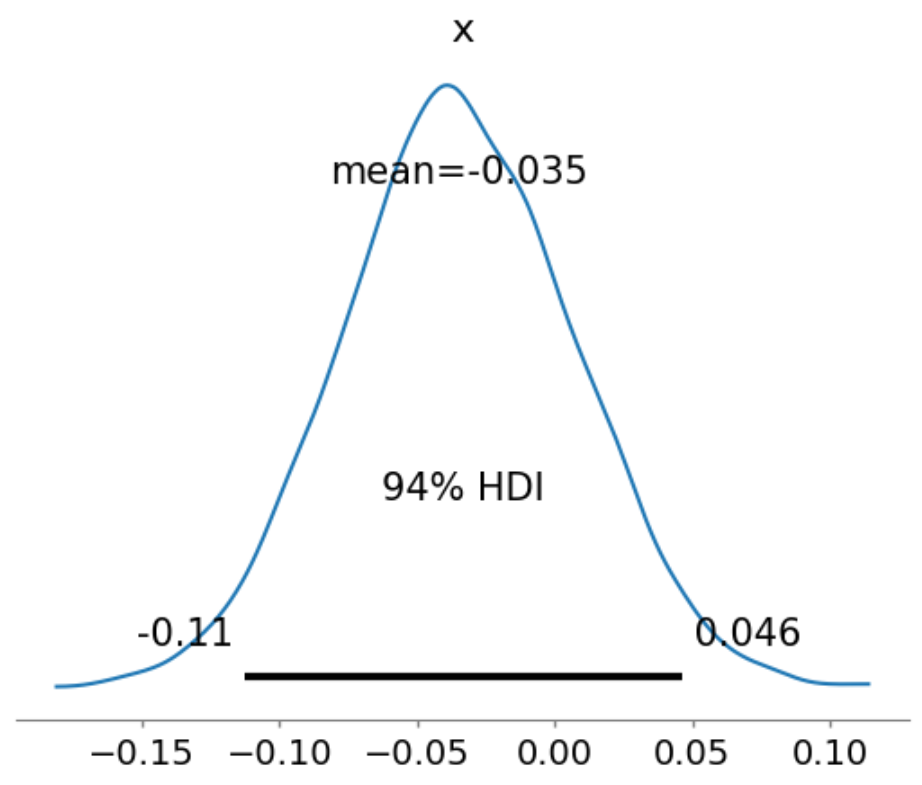
確認すると下側は-0.11となっているため、二日目の時点でも差があるとは言えない、と結論付けます。
2日目でも結論は出せませんでしたが、94%信用区間の幅が狭くなっており、このままデータを収集すれば何かしらの結論は出せそうな気配があります。
このまま、もともと設定していた「97%の確率でA(or B)の方が少しでも優れている」、または「10日経過する」という条件を満たすまでこれを繰り返していきましょう。
all_inference = []
all_inference.append(inference_1)
all_inference.append(inference_2)
all_diff = []
all_diff.append(diff_1)
all_diff.append(diff_2)
# 逐次的に日毎で事後分布を更新
for day in itertools.count(start=3):
print(f"Day {day}")
# モデルに新しい観測データを追加
with model:
observations_a_n = generate_synthetic_data(true_accuracy_a, daily_size)
observations_b_n = generate_synthetic_data(true_accuracy_b, daily_size)
# 事後分布を更新するために新しい日次データを追加
pm.Binomial(f'daily_A{day}', n=daily_size, p=accuracy_a, observed=sum(observations_a_n))
pm.Binomial(f'daily_B{day}', n=daily_size, p=accuracy_b, observed=sum(observations_b_n))
# 事後分布のサンプルを取得
inference_n = pm.sample(progressbar=False)
all_inference.append(inference_n)
# 差を計算
diff_n = inference_n.posterior.B - inference_n.posterior.A
all_diff.append(diff_n)
# 信用区間の計算
lower_bound = np.percentile(diff_n, 3)
upper_bound = np.percentile(diff_n, 97)
print(f"94% Confidence Interval: ({lower_bound:.3f}, {upper_bound:.3f})")
if lower_bound > 0:
print(f"Day {day}: B outperforms A")
break
else:
print(f"There is no significant difference between A and B")
if day == 10:
print(f"No statistically significant difference was observed")
breakこれを実行したところ、以下の結果が得られました。
Day 3
94% Confidence Interval: (-0.069, 0.056)
There is no significant difference between A and B
Day 4
94% Confidence Interval: (-0.054, 0.055)
There is no significant difference between A and B
Day 5
94% Confidence Interval: (-0.038, 0.059)
There is no significant difference between A and B
Day 6
94% Confidence Interval: (-0.025, 0.063)
There is no significant difference between A and B
Day 7
94% Confidence Interval: (-0.016, 0.069)
There is no significant difference between A and B
Day 8
94% Confidence Interval: (-0.001, 0.075)
There is no significant difference between A and B
Day 9
94% Confidence Interval: (0.003, 0.073)
Day 9: B outperforms A無事9日目でBの方が優れているという結論が得られました。
また、事後分布の推移をグラフも確認します。まずはAとBそれぞれの事後分布です。
az.plot_forest(
all_inference,
kind="forestplot",
combined=True,
legend=False,
textsize=7,
figsize=(3, 3),
show=True
)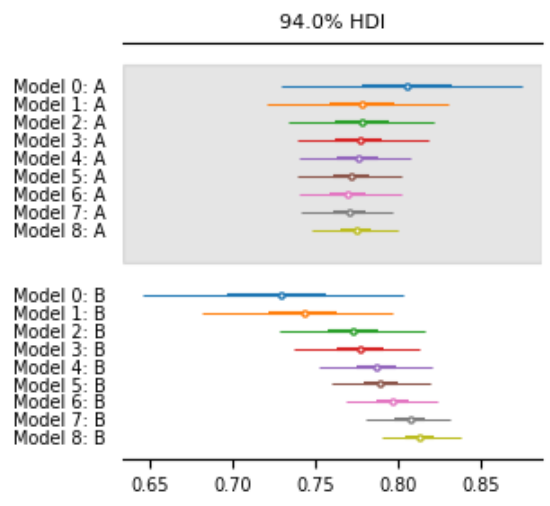
これを見る限り、日が経過するごとに信用区間の幅が狭くなり、真の値付近に分布が遷移していることが分かります。
併せて差の分布についても確認します。
az.plot_forest(
all_diff,
kind="forestplot",
combined=True,
legend=False,
figsize=(3, 3),
show=True
)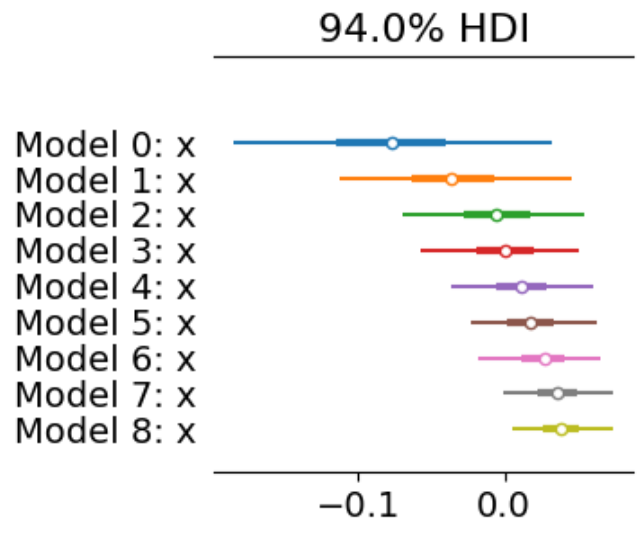
信用区間の幅が狭くなり、9日目の時点で下側の確率点が0を超えていることが分かります。
ベイズ推定によるABテストまとめ
ここまででモデルBの方が良いと判定され、ベイズ推定を用いてABテストを実施することができました。
事後分布を見ることで、どれぐらいの確率でどっちがどれぐらい優れている、のような評価がしやすいので非常に便利です。頻度論に基づく仮説検定と比べて、取り回しがしやすく、ビジネスの場で生かしやすいです。
参考文献
本記事のようなベイズ統計を学ぶ際には下記の書籍が非常に良いと思います。
完全独習 ベイズ統計学入門: https://amzn.to/41ag4Wa
Pythonでスラスラわかる ベイズ推論「超」入門: https://amzn.to/3VcQ08Y
前者はかなり優しく、導入の書籍として非常に良いです。その後、後者の方を用いながら実装しながら学んでいくのが良いと思います。
留意点
この問題を解くにあたって非常に強い仮定をいくつも置いたため、シミュレーションがうまくいっていると言えます。かなり多くの仮定を置いているので網羅は困難ですが、大きなものでいうと以下です。
- 評価指標の設計が明に定まっており、分布の定義が容易
- システム的な理想環境が整っている
- データに不備や欠損などが無く、観測値を信じてよい
- オンラインのラベルが当日中に収集可能
- データ・モデルそれぞれ及び組み合わせに想定外のバイアスが乗っていない
- 理想的なランダムサンプリングができている
上記については網羅するのは非常に難しいですが、本記事においては上記の解決の役に立つであろう書籍を紹介します。
下記は評価指標の設計の力になると思います。
評価指標入門: https://amzn.to/49jlGj2
下記はABテスト自体の設計の力になると思います。
A/Bテスト実践ガイド: https://amzn.to/4eQ9rvo
Pythonで学ぶ効果検証入門: https://amzn.to/3Z9V0MT
統計を学びたい方へ
統計検定2級 or 3級取得までマンツーマンで教えるサービスを提供しています。
統計を学び、資格取得を目指す方はまずは無料の初回コンサルをお申込みください。
コメント